sync.Pool
sync.Pool 数据类型用来保存一组可独立访问的临时对象。请注意这里加粗的“临时”这两个字,它说明了 sync.Pool 这个数据类型的特点,也就是说,它池化的对象会在未来的某个时候被毫无预兆地移除掉。
使用方法:
- New:这个字段的类型是函数 func() interface{}。当调用 Pool 的 Get 方法从池中获取元素,没有更多的空闲元素可返回时,就会调用这个 New 方法来创建新的元素。如果你没有设置 New 字段,没有更多的空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
- Get:调用这个方法,就会从 Pool取走一个元素,这也就意味着,这个元素会从 Pool 中移除,返回给调用者。不过,除了返回值是正常实例化的元素,Get 方法的返回值还可能会是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回),所以你在使用的时候,可能需要判断。
- Put:这个方法用于将一个元素返还给 Pool,Pool 会把这个元素保存到池中,并且可以复用。但如果 Put 一个 nil 值,Pool 就会忽略这个值。
缓冲池实例: byte slice 是经常被创建销毁的一类对象,使用 buffer 池可以缓存已经创建的 byte slice。如下所示:
1 | var buffers = sync.Pool{ |
上述代码有内存泄露的问题。
实现原理
数据结构如下所示:
1 | type Pool struct { |
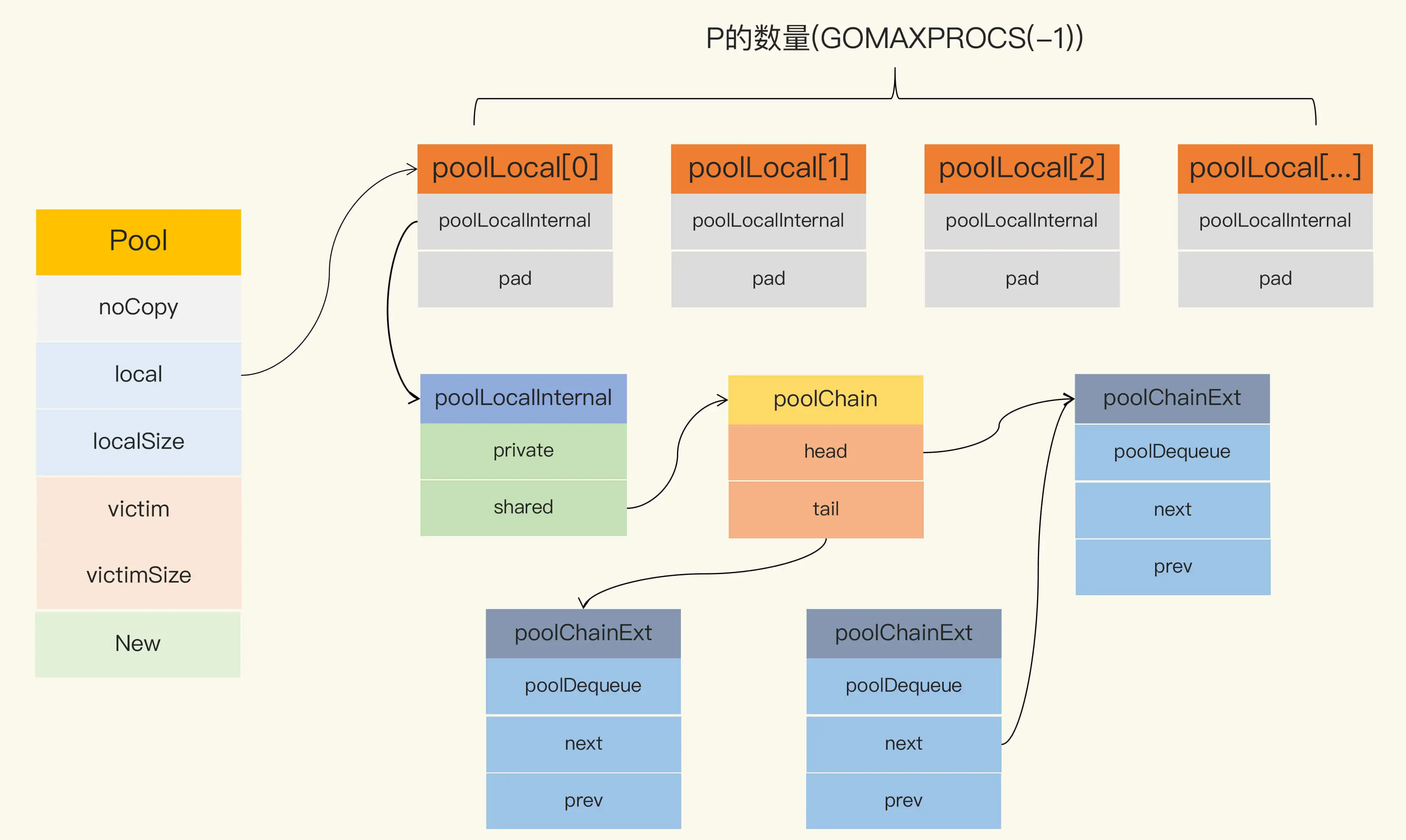
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim,这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了。
垃圾回收时 sync.Pool 的处理逻辑:
1 | func poolCleanup() { |
所有当前主要的空闲可用的元素都存放在 local 字段中,请求元素时也是优先从 local 字段中查找可用的元素。local 字段包含一个 poolLocalInternal 字段,并提供 CPU 缓存对齐,从而避免 false sharing。
cpu分层读取,L1, L2, L3, 内存。当读取某一个值x做读写操作时,并不是只读取一个值,而是按块来读取(因为cpu读取,很可能会用到相邻的数据,比如把y也一起读取进去了),此时如果另一个cpu操作y,就会出现伪共享问题。解决方式:在x, y插入一些无用的内存,将y排出当前的缓存行即可
poolLocalInternal 也包含两个字段:private 和 shared。
- private,代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
- shared,可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer)
Get
1 | func (p *Pool) Get() interface{} { |
首先,从本地的 private 字段中获取可用元素,因为没有锁,获取元素的过程会非常快,如果没有获取到,就尝试从本地的 shared 获取一个,如果还没有,会使用 getSlow 方法去其它的 shared 中“偷”一个。最后,如果没有获取到,就尝试使用 New 函数创建一个新的。
getSlow 方法如下:
1 | func (p *Pool) getSlow(pid int) interface{} { |
它首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
Put
Put 的逻辑相对简单,优先设置本地 private,如果 private 字段已经有值了,那么就把此元素 push 到本地队列中。
1 | func (p *Pool) Put(x interface{}) { |
Sync.Pool 的问题
内存泄漏
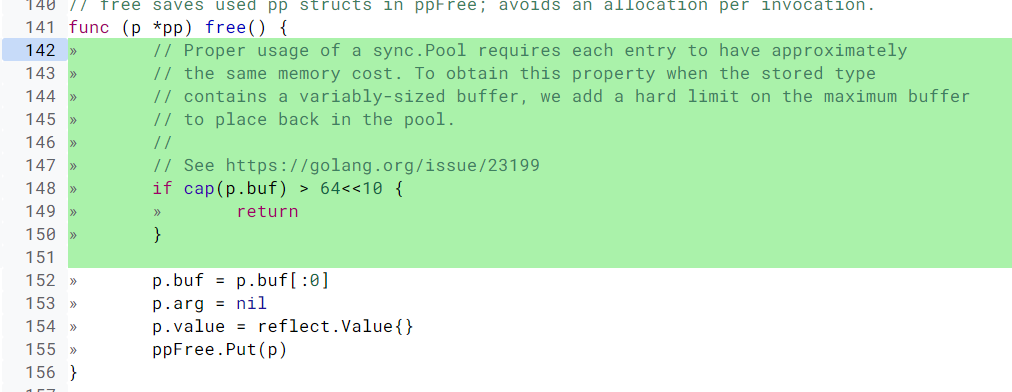
最开始实现的 bytes.Buffer是有问题的, 取出来的 bytes.Buffer 在使用的时候,我们可以往这个元素中增加大量的 byte 数据,这会导致底层的 byte slice 的容量可能会变得很大。这个时候,即使 Reset 再放回到池子中,这些 byte slice 的容量不会改变,所占的空间依然很大。而且,因为 Pool 回收的机制,这些大的 Buffer 可能不被回收,而是会一直占用很大的空间,这属于内存泄漏的问题。
所以 在使用 sync.Pool 回收 buffer 的时候,一定要检查回收的对象的大小。如果 buffer 太大,就不要回收了,否则就太浪费了。
内存浪费
除了内存泄漏以外,还有一种浪费的情况,就是池子中的 buffer 都比较大,但在实际使用的时候,很多时候只需要一个小的 buffer,这也是一种浪费现象。要做到物尽其用,尽可能不浪费的话,我们可以将 buffer 池分成几层。首先,小于 512 byte 的元素的 buffer 占一个池子;其次,小于 1K byte 大小的元素占一个池子;再次,小于 4K byte 大小的元素占一个池子。这样分成几个池子以后,就可以根据需要,到所需大小的池子中获取 buffer 了。
在标准库 net/http/server.go 中的代码中,就提供了 2K 和 4K 两个 writer 的池子

Worker Pool
有的时候,我们就会创建一个 Worker Pool 来减少 goroutine 的使用。比如,我们实现一个 TCP 服务器,如果每一个连接都要由一个独立的 goroutine 去处理的话,在大量连接的情况下,就会创建大量的 goroutine,这个时候,我们就可以创建一个固定数量的 goroutine(Worker),由这一组 Worker 去处理连接。
gammazero/workerpool:gammazero/workerpool 可以无限制地提交任务,提供了更便利的 Submit 和 SubmitWait 方法提交任务,还可以提供当前的 worker 数和任务数以及关闭 Pool 的功能。
ivpusic/grpool:grpool 创建 Pool 的时候需要提供 Worker 的数量和等待执行的任务的最大数量,任务的提交是直接往 Channel 放入任务。
dpaks/goworkers:dpaks/goworkers 提供了更便利的 Submit 方法提交任务以及 Worker 数、任务数等查询方法、关闭 Pool 的方法。它的任务的执行结果需要在 ResultChan 和 ErrChan 中去获取,没有提供阻塞的方法,但是它可以在初始化的时候设置 Worker 的数量和任务数。
类似的 Worker Pool 的实现非常多,比如还有panjf2000/ants、Jeffail/tunny 、benmanns/goworker、go-playground/pool、Sherifabdlnaby/gpool等第三方库